Scheduled batch jobs are used to run tasks on specified time, these tasks can include but are not limited to aggregation(ex. report generation), data transfer(ex. loading data to search engine), and bulk transactional execution(ex. terminating orphan order).
However, as modern applications become more complex and demand higher reliability and responsiveness, the limitations of scheduled batch jobs become increasingly apparent. This article delves into the reasons why programmers should reconsider using scheduled batch jobs and explores more dynamic alternatives that can improve efficiency and system robustness.
Table of Contents
Challenges of Scheduled Batch Jobs
1. Concentrated Load at Specific Times
Scheduled batch jobs typically run during off-peak hours to minimize the impact on system performance. This scheduling can create significant spikes in CPU usage, memory, and I/O operations, which can strain the infrastructure and lead to increased maintenance costs and potential downtime.
2. All-or-Nothing Execution
Batch jobs often process data in large chunks, making them vulnerable to failure of entire chunk if any part of the task encounters an error. For instance, if a batch job processes thousands of transactions and one transaction fails due to a data issue, the entire batch may terminate prematurely, requiring manual intervention to identify and correct the issue before rerunning the job.
3. Delayed Problem Detection
Since batch jobs run at predetermined times, any issues with the job—such as logic errors or data anomalies—can remain undetected until the job executes. This is more problematic since batch processing would have already caused issues with multiple data sets. Fixing the issue would often require manual fixing of these batch data and rerunning the task.
4. Data Inconsistency
One of the use cases of scheduled job is to change state of transactional data. The sequential nature of batch processing can lead to data inconsistencies. Consider the example of a e-commerce coupon. The coupon has expiration time after which a user can no longer use the coupon. A naive way of implementing this would be to keep state of a coupon in the database and expiring it using scheduled batch job.
class Coupon(
val expireAt: LocalDateTime,
var state: State, // updated through scheduled job
) {
enum class State {
ACTIVE,
EXPIRED,
USED,
;
}
fun use() {
require(state == State.ACTIVE)
// use internal logic
}
}This maybe okay when the size of data set is small and time taken to change state is minimal. However, consider when the data set grows to millions of coupons. The scheduled task might require tens of minutes to finish execution. This means the last chunk to be processed would be in a inconsistent state where coupons can still be used even after the expiration time. Also when a job fails, data would be in inconsistent state until it is run successfully again.
5. Linear Increase in Execution Time
Growth in data set size can cause increase in execution time of scheduled jobs. Especially the jobs that read multiple data, processed them one by one, and write the result, can experience linear increase in execution time as the data set grows.
6. Complexity in Testing
Testing batch jobs can be particularly challenging. These jobs required setup of multiple test data to mimic actual behavior as it processes large chunk of data at once in actual production environment. This can be more challenging than writing test for processing of single data.
Alternatives to Batch Jobs
Root cause of challenges with scheduled batch jobs lies within the name itself; schedule and batch. Let’s explore some of the ways scheduled batch jobs can be avoided to achieve resilience and robustness. These approaches not only balances the load on system resources but also ensures that data is processed and available immediately, enhancing the responsiveness of applications.
1. Dynamic State Using Time Based Logic
Implementing dynamic time based logic allows computation of logic at runtime instead of pre-computation using schedule job.
Consider the example of coupon from the previous section. State of the coupon was persisted in database and required scheduled job to change its state. However, time based state determination can remove the need for the persistence of state and scheduled job altogether.
class Coupon(
val expireAt: LocalDateTime,
) {
// calculated on method call
val state: State get() {
val now = LocalDateTime.now()
return if (now < expireAt) {
State.ACTIVE
} else {
State.EXPIRED
}
}
enum class State {
ACTIVE,
EXPIRED,
USED,
;
}
fun use() {
require(state == State.ACTIVE)
// use internal logic
}
}2. Individual Processing Using Delayed Message
Individually processing of message also helps spreading out the load. Some message brokers such as RabbitMQ support delayed message feature which allows for execution of task at later time. Let’s look at the example of coupon again.
class Coupon(
var state: State, // updated through delayed message
) {
enum class State {
ACTIVE,
EXPIRED,
USED,
;
}
fun use() {
require(state == State.ACTIVE)
// use internal logic
}
}This time around, the expiration of coupon is triggered by delayed message. The coupon has requirement of expiring after 10 minutes of issuance if unused. The overview of the flow would be like follow.
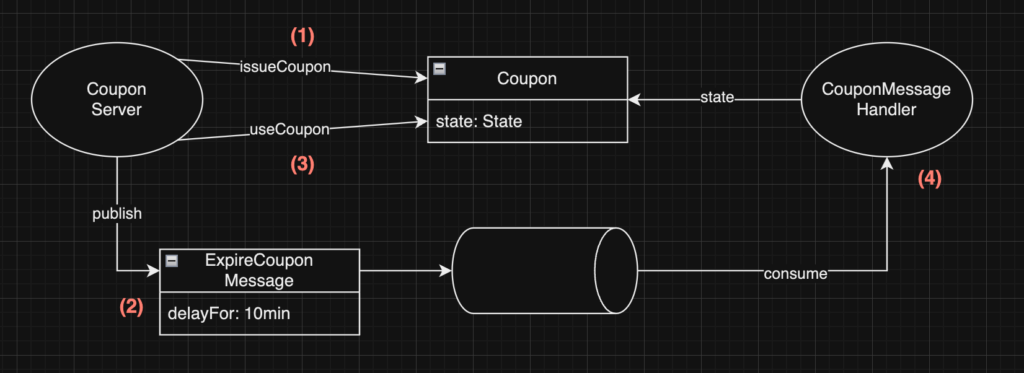
- Coupon is issued
- Immediately after issuing coupon, message to expire coupon is published with delayed time of 10 minutes
- Coupon is used within the 10 minute window
- After 10 minutes for issuing, message handler picks up
ExpireCouponMessageand check if the coupon is used. Handler expires the coupon if unused, handler skips processing if coupon is used
3. User-Initiated Processing
Implementation can also allow users to trigger processing tasks. This approach may increase the complexity of interaction between client and server, but has added benefit of avoiding unnecessary tasks. Let’s look at the final example using coupons.
class Coupon(
val expireAt: LocalDateTime,
var state: State, // updated through expiration initiated by user
) {
enum class State {
ACTIVE,
EXPIRED,
USED,
;
}
fun use() {
require(state == State.ACTIVE)
// use internal logic
}
}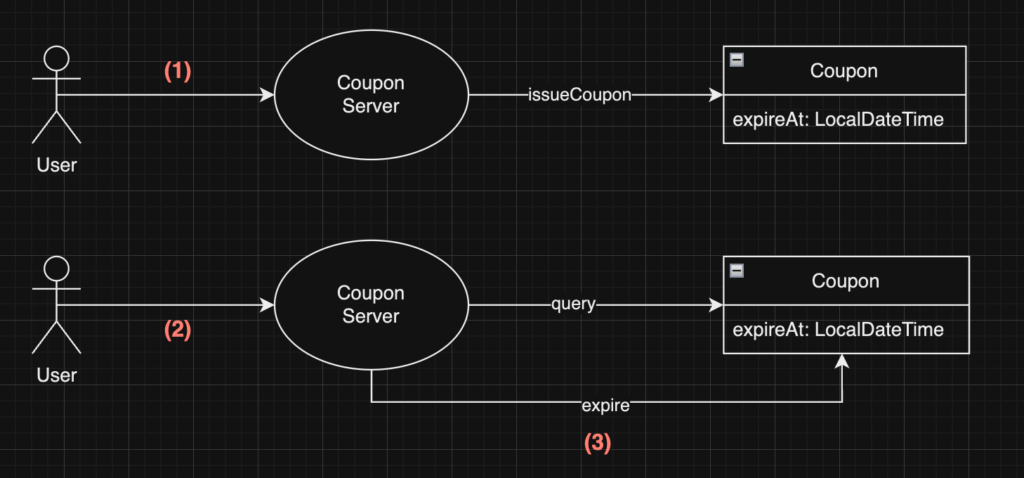
- User is issued a coupon
- After some time, user returns to the service and checks list of issued coupons
- If coupons with expired time exists, expire them
There are more adequate use cases for these alternatives, but I’ve stuck with expiring coupon example for the sake of consistency. These examples only introduce the ideas from higher view, but figuring out the actual implementation and adequate use case wouldn’t be too hard.
Appropriate Use Cases for Scheduled Batch Jobs
Despite the drawbacks, scheduled batch jobs are still suitable for certain scenarios:
- High Resource Consumption Tasks: Some tasks are just too resource-intensive to run repeatedly and may want to be delayed. This can include loading of data into search engine that indexes on data insert or building an AI model using user behavior data.
- No Suitable Task Trigger Exist: If there is no straight forward way to trigger task other than time based scheduling, there would be no other way except for scheduled batch job. For example Backup of data using time based trigger would make the most sense.